Not a Fan of the Empty Catch
We’ve been having a bit of trouble with a small piece of software on a customer site. It’s just not working and there are no indications of why. So I cracked open the source and found a light dusting of these…
try
{
SqlConnection = new SqlConnection(connectionString);
//the rest of the Sql code
}
catch (SqlException)
{
}
Oh look, it’s an empty catch. An empty catch is about as justifiable as a goto – I’m not saying that you should never use one, just that you need to have a good hard think about what you’re actually doing and consider carefully whether or not you’ve got the structure of your code correct.
The case against is easy to see above; although it may be normal for one type of SqlException to be thrown and ignored (perhaps as the result of a deadlock), you can’t guarantee that every SqlException is thrown for that reason. In the deadlock example your code should more follow this pattern.
try
{
SqlConnection = new SqlConnection(connectionString);
//the rest of the Sql code
}
catch (SqlException ex)
{
if (1205 == ex.Number) //deadlock (see http://technet.microsoft.com/en-us/library/cc645603.aspx)
{
//we ignore deadlocks
}
else
throw;
}
This tests the SqlException to see if it’s a deadlock and ignores it – if it’s not a deadlock then it re-throws it.
I would argue however that this doesn’t go far enough. Exceptions should not be used for flow control which means that the very fact an exception has been thrown indicates that something has gone wrong. If you’re not going to handle that in code then the very least you should do is enable someone to find out that it happened.
There are many logging and debugging gizmos out there (such as log4net) and they usually contain a concept of levels of information. It would be a rare circumstance indeed where an empty catch was preferable to a minimal debug log, e.g.
try
{
SqlConnection = new SqlConnection(connectionString);
//the rest of the Sql code
}
catch (SqlException ex)
{
if (1205 == ex.Number) //deadlock (see http://technet.microsoft.com/en-us/library/cc645603.aspx)
{
log4netInstance.Debug("SomeOperation caught Sql deadlock => {0}", ex.ToString());
}
else
throw;
}
If this exception is normal and the app is expected to cope then you can turn the “Debug” level of logging off in configuration. If the app starts having problems then you can turn the “Debug” level back on and see all the exceptions that are being thrown. A subtle little thing like this can make a big difference.
On the one hand we have a quick phone call to one of the customer’s IT pros to explain that their recent security audit has resulted in them accidentally revoking the app’s authentication to the DB and that perhaps they’d like to reverse that.
On the other hand we have you, the developer, being sent to the customer’s site where you have to explain to some very senior people why your application has stopped working and what you intend to do about the poor quality, unreliable piece of software that you’ve supplied.
Never underestimate what can happen to your app on a customer site: Murphey’s Law is one of the fundamental underpinnings of computer science.
Reading Time: 5minutesSurface RT: It’s a Nice Idea.
I was on campus at Hull last week and pretty much as I walked in the door the ICT dept. jammed a Windows Surface RT into my hands. “It’s useless,” said a man in a Where Would You Think t-shirt, “enjoy!”.
I was quite excited about getting a Surface RT however, mostly because a lot of our customers do significant amounts of business when out-and-about. Developing for Android and iPad is a bit of a pig for Seed as it’s basically a Windows software house (although we do do it). So having something based on an ARM processor but that runs Windows must be a pretty major innovation for us, right? I mean most of our apps are pure .NET so you’d think it would be child’s play to get them onto the Surface RT right?
Now I understand, from a technical point of view, why Microsoft may want to do this; Windows is still in a transition. Microsoft don’t really want anyone fiddling with that old Win32 stuff because it’s dangerous, but a lot of legacy apps still need it. Whilst Microsoft continue to provide access to the Win32 interface those applications aren’t going to stop using it. So they need to break the chain.
The reason it’s dangerous – indeed something that’s bugged Windows from the start – is that they’re trying to retrofit security. Basically Unix-like operating systems, of which iOS and Android are, start with the premise that as a user (or application) you’re not allowed to do anything. You are then granted permission to perform certain tasks. You can’t get at the soft underparts of the operating system unless you’re a superuser and in the case of iOS and stock Android devices they’re not letting you do it (although you can “root” most Android devices to get such access if you really want).
Windows however started life assuming that the user could do anything they wanted, so security simply wasn’t included at the start. This means that Windows has a heck of a lot more holes to plug than the other two platforms, and they’re not there yet. To clarify, we’re not just talking about hackers and viruses, but a lot of legitimate programmers have been using stuff in Windows – often because there’s no alternative – that can actually destabilise the system. Opening up the device to anything that would cross-compile for the ARM processor would mean they had exactly the same problems on the tablet as they do on the desktop.
Essentially we’re all still paying for a cock-up that Microsoft made in 1981.
There would be a half-way house though, as I mentioned before most of our apps are pure .NET which in theory can’t do anything nasty. The fact that RT is not open to pure .NET apps makes me scratch my head a little. I can’t help but wonder if perhaps the current .NET runtime (for desktop) isn’t quite a clean as it ought to be.
So, as a software developer I find the Surface RT frustrating, it has a desktop that I can’t use, I can’t write Windows Services (even in .NET), the only thing I can do is write store apps and even then it’s subtly different to writing a Windows Phone app.
Microsoft themselves have done a reasonably good job of getting their own apps onto Surface RT (e.g Skype, Lync) and there’s a smattering of the top apps that you’d expect to find – Facebook, Twitter, Kindle etc. but that’s about it. There is a woeful lack of applications for the platform. Not only that but even apps like Facebook and Twitter seem limited compared to their Android counterparts. They’re clunkier, it’s clearly that less attention has been paid to them.
So the big advantage of the Surface RT over an Android or iPad tablet is that it runs full Microsoft Office. That’s it. That’s the advantage and to be honest some of the alternative office packages that are available for Android are pretty good. In every other way it’s a worse platform than Android or iPad.
It even needs its own special charger rather than using Micro USB – although to be fair it uses a 12V supply whereas USB is 5V.
Annoying
What Microsoft have done is to pretty much guarantee failure of the platform.
Still, it must be useful for something, right? I mean it’s actually quite a good piece of hardware. They detachable keyboard thing works really well too.
It’s certainly better (hardware) than the cheap Chinese Android table I got a couple of years ago. So why don’t I run Linux or Android on it? Well I can’t because Microsoft have locked the bootloader. Before you scream “no fair!” almost everyone does these days, Android included. Some Android manufacturers however release unlocks for their bootloaders. HTC for instance generally do when the device is a couple of years old (via htcdev.com). I can’t see Microsoft doing this.
In conclusion, the Surface RT is not the platform for development that I’d hoped it would be; it’s not very useful for us to develop apps for. Yes it has Office which makes it a useful device to have around for meetings etc. and it’s a lot easier to get in hand luggage than a laptop. It lacks the I/O though to make it a useful presentation device and there’s no chance of running up Visual Studio even if I could put up with it running terribly slowly. For me it cannot replace a laptop for anything other than the most basic business use.
There are cheaper Android devices that are far more capable – and the lack of Microsoft Office on them isn’t really much of an issue. There are x86 based tablets that run full Windows and, whilst they might be a bit slow, are actually viable as a travel alternative to a laptop. Microsoft themselves even produce the Surface Pro series.
To cap it all off the lack of apps puts it way behind the competition as a social and media platform so I’m really struggling to find a use for it. I’ll let you know if I find something a little more involving of technology than this…
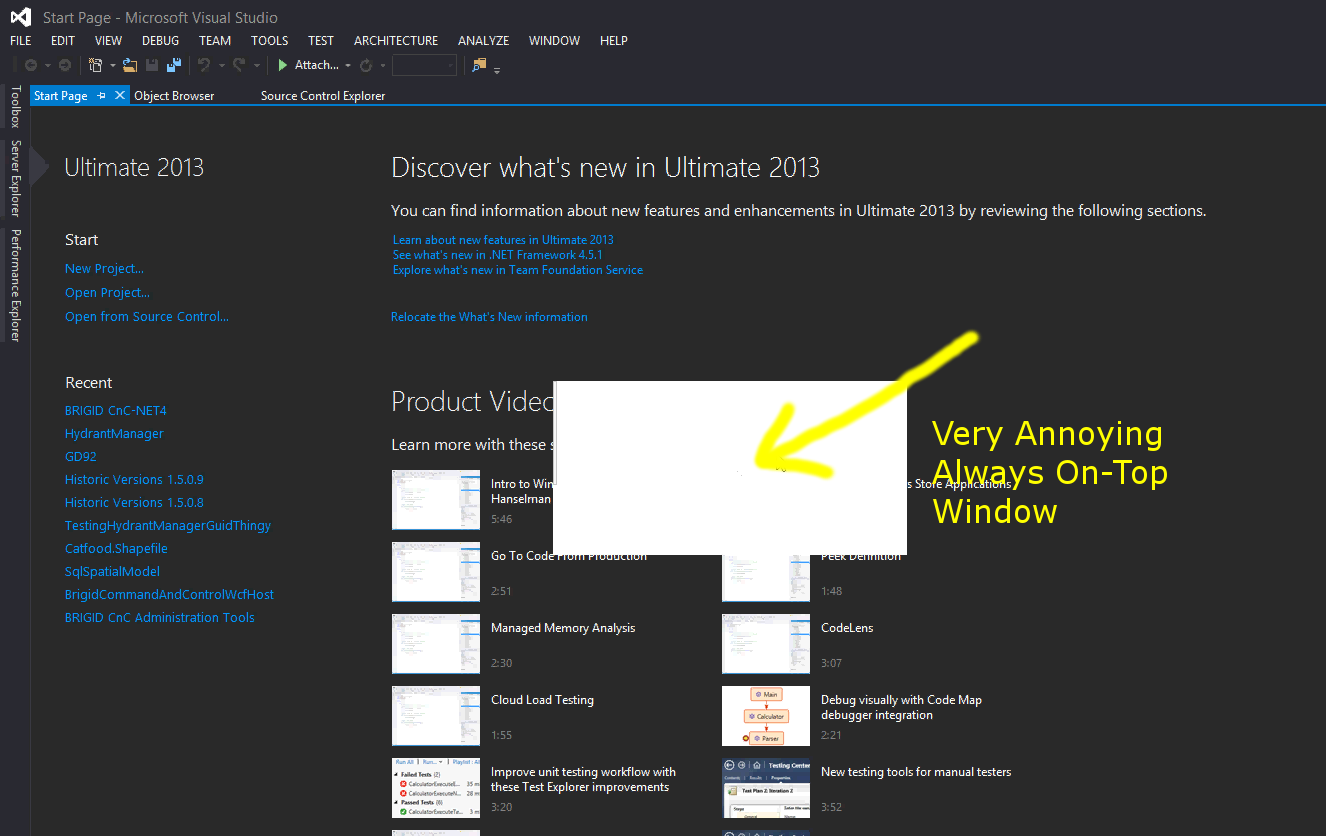
I’ve noticed a lot, particularly in Windows 8, that I get phantom windows. Perhaps the application wanted to create an invisible window but for some reason it gets displayed. This is very annoying, especially when it sits permanently on top of other windows like this little example here.
Thankfully there’s a quick and easy way to get rid of them using the rather handy Process Explorer from TechNet.
At the top of the app are several buttons, one of them looks a bit like a targeting system and is labelled "Find Window’s Process"
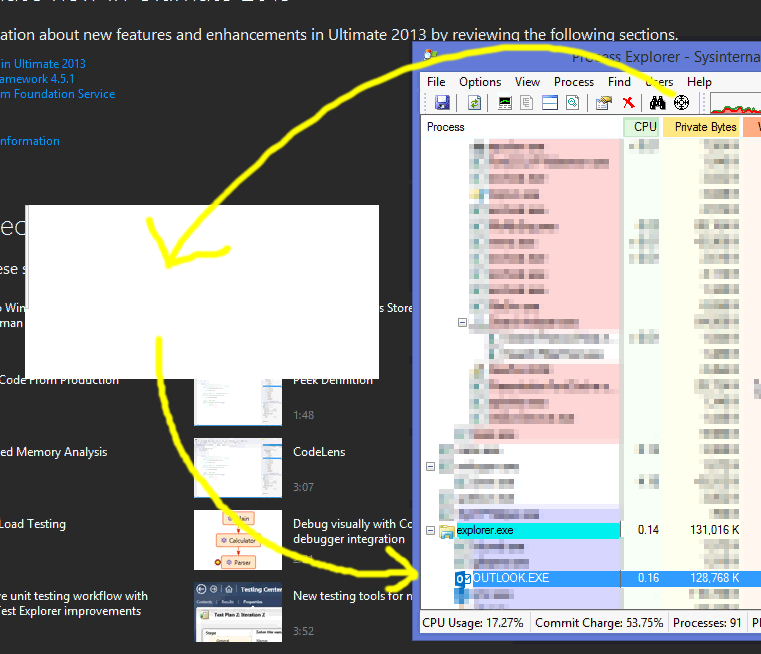
Simply drag that button onto the offending window and drop. Process Explorer will then highlight the process responsible, which you can deal with.
In this case it was Outlook and simply restarting the application fixed the problem.
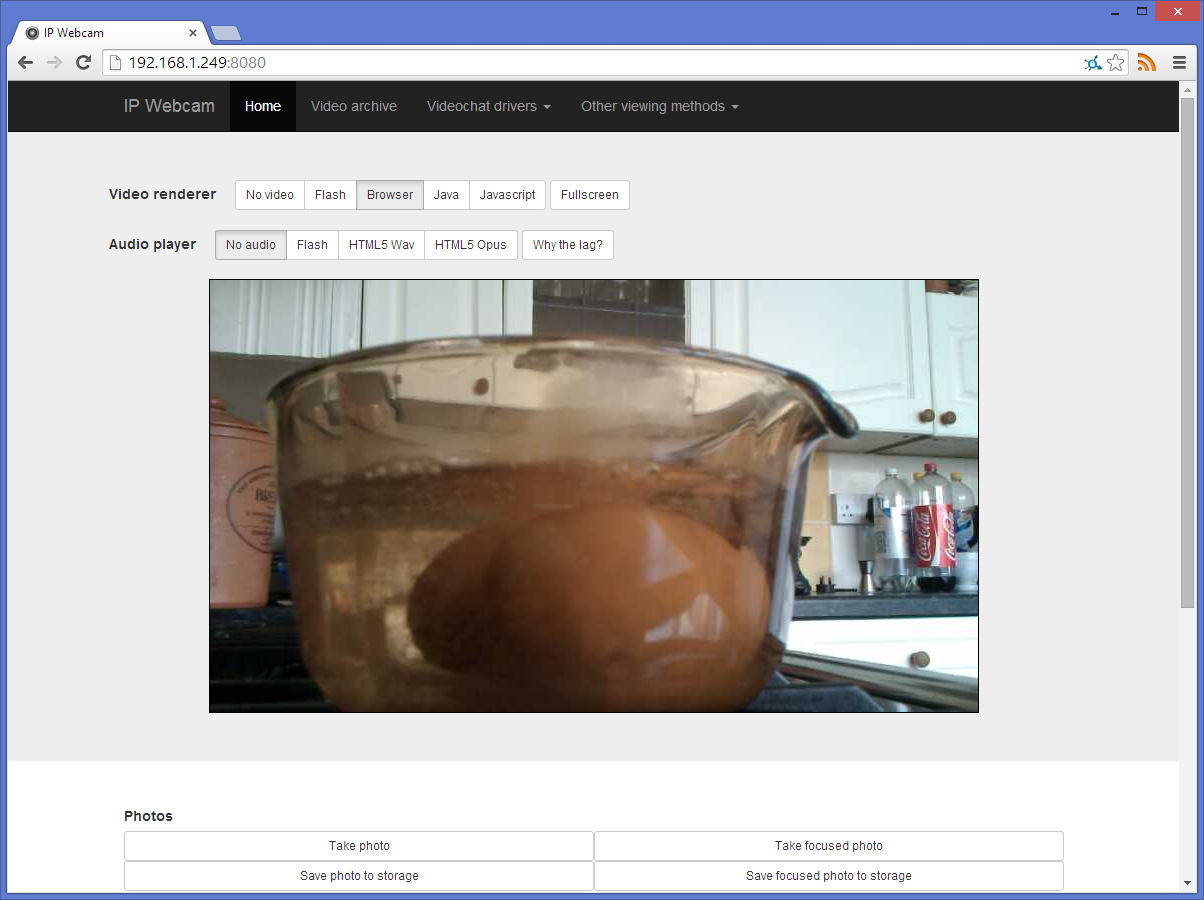
I end up using the IP Webcam Android application for all sorts of things. It’s really easy to prop or jam an Android device pointing at something you need to keep an eye on or even push the device somewhere where you just can’t get your head. Then fire up a web browser and monitor the output stream.
Today’s issue was that I forgot to boil some eggs for lunch, so I propped my Wildfire S against a spare pan and went back to the office. There I monitored the webcam and started the timer when I saw the eggs boiling. They were ready in perfect time.
…British APCO, or simply BAPCO is the Association of Public-Safety Communications Officials. At Seed we produce not only communications systems for the emergency services but many of the applications that use them: in-vehicle systems, hand-held systems for mobilisation and data capture and our Command Control mobilising system.
So being represented at BAPCO’s large annual event is important for us. In previous years we’ve piggy-backed on some of our partners’ stands but this year we decided that our portfolio was significant and mature enough that it warranted its own stand.
The results were pretty amazing, there was a real buzz around the stand with people from all over the emergency services and public safety spectrum coming to talk to us and find out more about who we are and what we do.
It was a lot of hard work though; it’s nearly a week later as I write this and I’ve just about finished tidying up all the admin. For the other guys it’s been a much longer road. I was able to simply turn up to the stand on the first day. There were weeks’ worth of preparation effort before that – design and planning. Then the guys had to put everything in the van, drive it to Manchester and get the stand set up. We don’t have people to do any of this for us, so it was great experience for our young software developers to be part of the process right from the graphical design to screwing shelves into the wall.
They were also in the front line on the stand, talking to people and demonstrating our software. In the average business only very senior technical people get to do this, so to be able to give them that kind of experience – and just the experience of being at such an event – is a great benefit.
It wasn’t all work and no play though. We had some fun, such as the reaction training (computer) game at the official dinner – well there was only ever going to be one winner of that! We now know who plays the most shoot-em-ups too, and it wasn’t who we thought.
As a business, BAPCO 2014 gave Seed some great opportunities. Firstly we were able to connect with our existing customers and partners. As we don’t have any customer relationship managers every opportunity to spend time with the people we currently do business with, to talk about openly about their needs and where they see those needs going is really important. Getting those discussions out from drab meeting rooms and into an environment of seemingly limitless possibility is also important because at Seed we’re always looking forward, trying to work out ways that we can use technology to benefit our customers and our society.
We were also able to get the message of who Seed are, what we do and why we’re different to a much wider audience. Sure just about everyone in the Fire Service has heard of Seed but not many knew that nearly a third of England’s Fire Services have a Seed system. Not many realised that we started back in 2005 and that since then we’ve grown a lot; we’re not just in-vehicle terminal (MDT) providers any more, we have a full portfolio ranging from data capture to our own Command and Control mobilising system.
Seed is not limited to the Fire Service either – some of our products are as applicable to other emergency services as they are to Fire and further even that that. Our mobile forms product for instance is applicable anywhere where field workers have to fill in forms that need to be centrally collated.
Being able to stand in a room where most of the UK’s public safety organisations are represented and give those messages loudly and clearly is a hugely positive thing for us. We’re all very glad we did it. I enjoyed it too, sure it was tiring but it was very definitely worth the effort.
It’s no secret that I am not an ORM fan. Actually that’s a little harsh, ORMs bring some significant advantages and it’s not just having an object orientated view of a database – a lot of junior developers just don’t know SQL and they can save a massive amount of development time. They also discourage people from infecting the code-base with SQL which can prove a real maintenance headache. So in many ways ORMs are a good thing.
Unfortunately using an ORM can result in serious database abuse. Not so long ago I profiled some of the LINQ-to-SQL that one of our products uses and I nearly had kittens (some of that’s mentioned in this article). It was making thousands of unnecessary round trips to SQL Server to pick up individual records when one query could have got everything we needed.
A project that my team have just inherited demonstrates a different kind of database abuse rather neatly. There’s a web service that basically just provides a view of the DB. One of the methods does this…
Which is fine, apart from the fact that it transpires that it’s perfectly legitimate to have duplicate keys in the database (it’s not our DB). The Web Service is consumed by our remote client and we’d rather not be sending that any duplicates – so I modified the LINQ to eliminate them. The situation is slightly more complex than just using .Distinct() because in the case of duplicates what we actually want is the later record, according to the Added datetime field.
The .GroupBy groups the records by the key, then the following select only returns one record, the one with the highest “Added”. The result of this is an IEnumberable<Street> so the .OrderBy etc. will work just fine. It doesn’t work though, it throws a SQLException because the SQL that the Entity Framework generates contains the “Added” column in the order by clause twice. So I thought I’d profile the SQL Server an see exactly what it was trying to do…
SELECT TOP (500) [t4].[test], [t4].[GUID], [t4].[ParishGUID], [t4].[Name], [t4].[Active], [t4].[Added], [t4].[Created]
FROM (
SELECT [t1].[value]
FROM (
SELECT UPPER([t0].[GUID]) AS [value]
FROM [dbo].[Street] AS [t0]
) AS [t1]
GROUP BY [t1].[value]
) AS [t2]
OUTER APPLY (
SELECT TOP (1) 1 AS [test], [t3].[GUID], [t3].[ParishGUID], [t3].[Name], [t3].[Active], [t3].[Added], [t3].[Created]
FROM [dbo].[Street] AS [t3]
WHERE (([t2].[value] IS NULL) AND (UPPER([t3].[GUID]) IS NULL)) OR (([t2].[value] IS NOT NULL) AND (UPPER([t3].[GUID]) IS NOT NULL) AND ([t2].[value] = UPPER([t3].[GUID])))
ORDER BY [t3].[Added] DESC
) AS [t4]
ORDER BY [t4].[Added], UPPER([t4].[GUID]) DESC, [t4].[Added] DESC
Holy Truffle Oil Batman! That’s bonkers! What makes matters worse is that even if I correct the SQL the query times out and there are only 30,000 records in the DB. Because it’s bonkers.
So I started to think about how I’d actually do it in SQL. This is my first attempt, now I’m not saying it’s optimal. I think there may be ways I could improve it but it works and with 30,000 records it returns pretty much instantly.
SELECT [GUID]
,[ParishGUID]
,[Name]
,[Active]
,[Added]
,[Created]
FROM
(SELECT *, ROW_NUMBER() OVER(ORDER BY [GUID]) RN FROM
(SELECT *
,RANK() OVER (PARTITION BY [GUID] ORDER BY Added,NEWID()) RK
FROM dbo.Street
WHERE @takeAll = 1 OR Added >= @added) DEDUPE
WHERE RK=1) CHUNK
WHERE RN > @start and RN <= @start+@take
The Entity Framework is kind enough to provide a generic ExecuteQuery<T> method on the DataContext so I’ll be writing a new method in the DAL effectively to override Entity Framework’s toxic SQL generation in this case. I suspect my new method won’t be lonely for long.
Reading Time: 2minutesOne thing about C# style that I get asked quite a lot is why I tend to write if statements like this…
if (null != args)
{
It’s not how most people think. It seems far more logical written this way round…
if (args != null)
{
It’s actually a hang-on from my days as a plain old C developer, most of the time it’s not relevant to C# but there’s one particular instance where it is.
bool someBoolean = false;
bool someOtherBoolean = true;
if(someBoolean = someOtherBoolean)
{
Console.WriteLine("The if condition evaluated to true!");
}
Console.WriteLine(String.Format("someBoolean is [{0}], someOtherBoolean is [{1}]", someBoolean, someOtherBoolean));
So when we run this, we might not get the result we expect.
This is because in C# assignment operations have a result. Instead of comparing the two items in the if statement (==) we assigned the value in someOtherBoolean to someBoolean (=). Basically we just used = where we should have used ==, it’s an easy mistake to make and in this instance it compiles and runs, it just doesn’t do what we want, at all…
I actually wrote about this in an article some time ago, but back then I was talking about doing it deliberately, and as part of a work of extreme evil.
OK, so that’s a convoluted example and in reality you’re unlikely to cause yourself serious problems in C# because C# is very strict about the result of whatever’s in an if statement being Boolean. So if you did accidentally write this, it wouldn’t compile.
if(someObject = null)
{
someObject = new someType();
}
This is because the result of assigning null to someObject is null, which is not a Boolean.
However in C the equivalent will compile and will run. In C anything that evaluates to zero is treated as false and anything that evaluates to non-zero is treated as true.
This will crash every time, because we’re actually assigning NULL to the value someStruct. The result of that assignment is zero, which evaluates to false, so execution skips the contents of the if statement and goes directly to where the structure is accessed – the structure that we’ve just assigned to NULL.
This is my mobile phone, or cellphone if you will. It’s a HTC Wildfire S running cyanogenmod 9. Sure it was never an expensive phone but I didn’t get it because it was cheap, I got it because it was small.
I am notoriously hard on kit. Something like a mobile phone just gets shoved in my pocket and ends up doing whatever I do. Scaling roofs to find mobile phone signal is perfectly normal in my world, as is climbing into the loft, crawling into tight gaps and running out in a howling gale to rope the remains of the fence to something a little more stable.
Amongst my friends, many of whom have the same attitude to life as me, there is a catalog of broken phone screens. My little Wildfire S has lasted a few years now without any serious damage.
It is however getting a little long in the tooth. It never had even remotely enough memory to start with and fiddling it to make it think that a portion of the SD Card is actually internal memory isn’t the most reliable. It’s also suffering a bit with a lot of modern apps which are a getting a bit slow.
So I’m in the market for a replacement – I figured this should be easy as there are a lot of new “mini” phones on the market. Only they’re not, the new “mini” phones are only mini compared to their tablet-size counterparts.
The look of horrible confusion on the face of a mobile phone stores salesperson is one I’ve got well used to, “sorry, I’ll just repeat that. I’m looking for a small, tough smartphone. Not a 6 inch mini-tablet that will break as soon as I attempt to climb a ladder with it in my pocket.”
I’m never far from a PC, a laptop or a tablet. I don’t need a mobile mini-tablet, what I need is a smart-phone, something that fits in my pocket and allows me to check social media and run a few tracking and navigation apps and maybe listen to Buddy Guy.
Reading Time: 7minutesRound trips to SQL Server kill performance. It takes time to set up the command, get it to the SQL Server, then to parse it, search for and format the results then return them to the application. If you need lots of little pieces of information this can get extremely frustrating, especially when you get a call from your DBA about the “horrible” app that you’re developing.
Sometimes you can bring back a super-set of the data you need in one query rather than several smaller queries and you may find that filtering the data down to what you need in code is faster than hitting SQL Server with lots of small queries. It is subjective, of course. There’s always a level in database programming where the theory is fine but you don’t really know until you try it.
I found myself thinking that there must be a better way though. There are two scenarios I want to cover – let’s start with the simpler one.
My Selection Criteria is Complex – e.g. It Contains a List
Wanting to pass a list as an input parameter to SQL Server is a common problem, and one that I’m pleased to say Microsoft addressed in SQL Server 2005 with table valued parameters. Except that they didn’t implement it in Linq-to-Sql or Entity Framework which proves a bit of a headache.
Table valued parameters also need to be in the schema and that’s not always under the control of the app developer. So what do you do if you’re stuck in hard place where you can’t do it the right way?
Let’s say Northwind – Microsoft’s now ancient example company – was integrating to another system. That other system might want details of several customers. Helpfully they can provide us list of the IDs they require. This is easy if you’re typing the SQL in directly…
SELECT * FROM dbo.Customers WHERE CustomerID IN ('BERGS','GODOS','FURIB','GREAL')
You can of course build up the query text in code to be just like the above but you’d better pray that “Little Bobby Tables” never becomes a customer.
Naturally you can use a stored procedure to parse a CSV type string but whilst that’s not so open to a Sql injection attack it’s still pretty fragile.
A more robust way is to use XML. Here’s some C# with everything hardcoded so, as long as you have a Northwind somewhere, this should work via the magic of cut-and-paste (and editing the connection string).
private void GetCustomersByID(List<string> list)
{
//make an XML document listing the customer IDs
XElement doc = new XElement("customers");
list.ForEach(customer =>
doc.Add(new XElement("customer", new XAttribute("CustomerID", customer))));
//Connect to the SQL Server
using (SqlConnection connection = new SqlConnection(@"Server=(localdb)\v11.0;Integrated Security=true;Initial Catalog=Northwind"))
{
connection.Open();
using (SqlCommand getCustomers = connection.CreateCommand())
{
getCustomers.CommandType = System.Data.CommandType.Text;
//Command text uses the XML document to join to the target table as a way of selecting rows
//(there are other, probably better ways)
getCustomers.CommandText =
"DECLARE @hdoc INT " +
"EXEC sp_xml_preparedocument @hdoc OUTPUT, @xml " +
"SELECT [dbo].[Customers].[CustomerID], [CompanyName], [ContactName], [ContactTitle], [Address], [City], " +
"[Region], [PostalCode], [Country], [Phone], [Fax] FROM [dbo].[Customers]" +
"INNER JOIN OPENXML(@hdoc,'/customers/customer',1) WITH (CustomerID nchar(5)) req " +
"ON req.CustomerID = dbo.Customers.CustomerID " +
"exec sp_xml_removedocument @hdoc";
getCustomers.Parameters.AddWithValue("@xml", doc.ToString());
//bring the results back and display them
using (SqlDataReader resultsReader = getCustomers.ExecuteReader())
{
while (resultsReader.Read())
{
object[] values = new object[resultsReader.FieldCount];
resultsReader.GetValues(values);
Console.WriteLine(String.Join(", ", values.Select(x => x.ToString())));
}
}
}
}
So we make an XML document in C# – there are any number of ways of doing this, I chose LINQ’s XElement – and passed it to the SQL Command as a parameter. We then use OPENXML to open it as a rowset and inner join it to the target table, allowing us to bring back only the rows we want.
Of course there is an overhead in constructing the XML and parsing it in SQL Server and we must be aware of that, but this little trick does allow one to neatly work around some quite common problems.
Of course this example is a little trivial. It’ really only to demonstrate a technique. Where XML particularly wins – even over Table Valued Parameters – is that XML does not need to be a list of the same type. You could even specify groups of parameters or a complex structure enabling the SQL Server to make some informed choices about the data to return without having to issue multiple queries and incur unnecessary round-trip overhead.
I Want to Return Complex Information Made From Many Fragments of Data
This usually manifests itself when you need data from several tables where there isn’t a one-to-one relationship.
If the relationship is simple sometimes it’s quickest to use a join and just throw away the duplicated sections of the row. e.g. you might want a the customer details and their 50 most recent orders – you can accomplish this with a join but you’ll get a copy of the customer’s details with every order details so that’ll be 49 copies of the customer’s details that you don’t need. It may be faster than using 2 separate queries.
You can also return multiple result sets from a query or stored procedure. Scott Gu covers that quite adequately in LINQ-to-SQL Part 6. In the above example you could return two result sets, one containing the customers and the other containing the orders. You’d then have to link them in code, but provided there aren’t too many rows this can be a quick option.
If it’s details of just one customer that you need you could return one result set (the orders) and use OUT parameters in the query – that’s another option.
I mention these options first because XML may not be the right way to go, I’m really just presenting it as an option that you could take. To that end let’s look again at the Northwind database – perhaps we want to bring back a lot of information about a customer, maybe the orders they’ve placed and what was in those orders. This is a hierarchical data set, of course we could do this with multiple result sets but we’d have to join them up on the client side and that could get messy. Instead we can use SQL Server’s ability to output XML. Of course batting XML around the place instead of nice binary types is going to incur a significant overhead and that should be taken into account, but there is potential here.
SELECT [CustomerID]
,[CompanyName]
,[ContactName]
,[ContactTitle]
,[Address]
,[City]
,[Region]
,[PostalCode]
,[Country]
,[Phone]
,[Fax]
,(SELECT [OrderID]
,[CustomerID]
,[EmployeeID]
,[OrderDate]
,[RequiredDate]
,[ShippedDate]
,[ShipVia]
,[Freight]
,[ShipName]
,[ShipAddress]
,[ShipCity]
,[ShipRegion]
,[ShipPostalCode]
,[ShipCountry]
,(SELECT [OrderID]
,d.[ProductID]
,[Quantity]
,[Discount]
,[ProductName]
,[SupplierID]
,[CategoryID]
,[QuantityPerUnit]
,d.[UnitPrice] [OrderUnitPrice]
,p.[UnitPrice] [ProductUnitPrice]
,[UnitsInStock]
,[UnitsOnOrder]
,[ReorderLevel]
,[Discontinued]
FROM [dbo].[Products] p INNER JOIN [dbo].[Order Details] d ON p.ProductID=d.ProductID
WHERE d.OrderID=o.OrderId FOR XML PATH('OrderDetail'),ROOT('OrderDetails'),TYPE)
FROM [dbo].[Orders] o WHERE o.CustomerID=c.CustomerID FOR XML PATH('Order'),ROOT('Orders'),TYPE)
FROM [dbo].[Customers] c FOR XML PATH('Customer'),ROOT('Customers')
GO
The cunning bit here is using SQL Server’s subquery ability to produce a hierarchical XML dataset.
The root node is “Customers” containing multiple instances of “Customer”. Each Customer contains an “OrderDetails” element which is a list containing multiple instances of “OrderDetail”. This in turn has a “Products” element which is a list of “Product” items.
I won’t go into SQL Server’s ability to produce XML in any great deal suffice to say that it’s come a long way since 2005 and it’s now really quite powerful. I also accept that there may be better ways of achieving the above.
What I do need to mention is how to get this back to a C# app – don’t be tempted to use ExecuteScalar() – it will truncate long xml.
The following uses XmlReader which is in turn used with an XmlDocument. This is the asynchronous model which allows a little more responsiveness in the GUI, but does mean a lot of Dispatcher.Invoke().
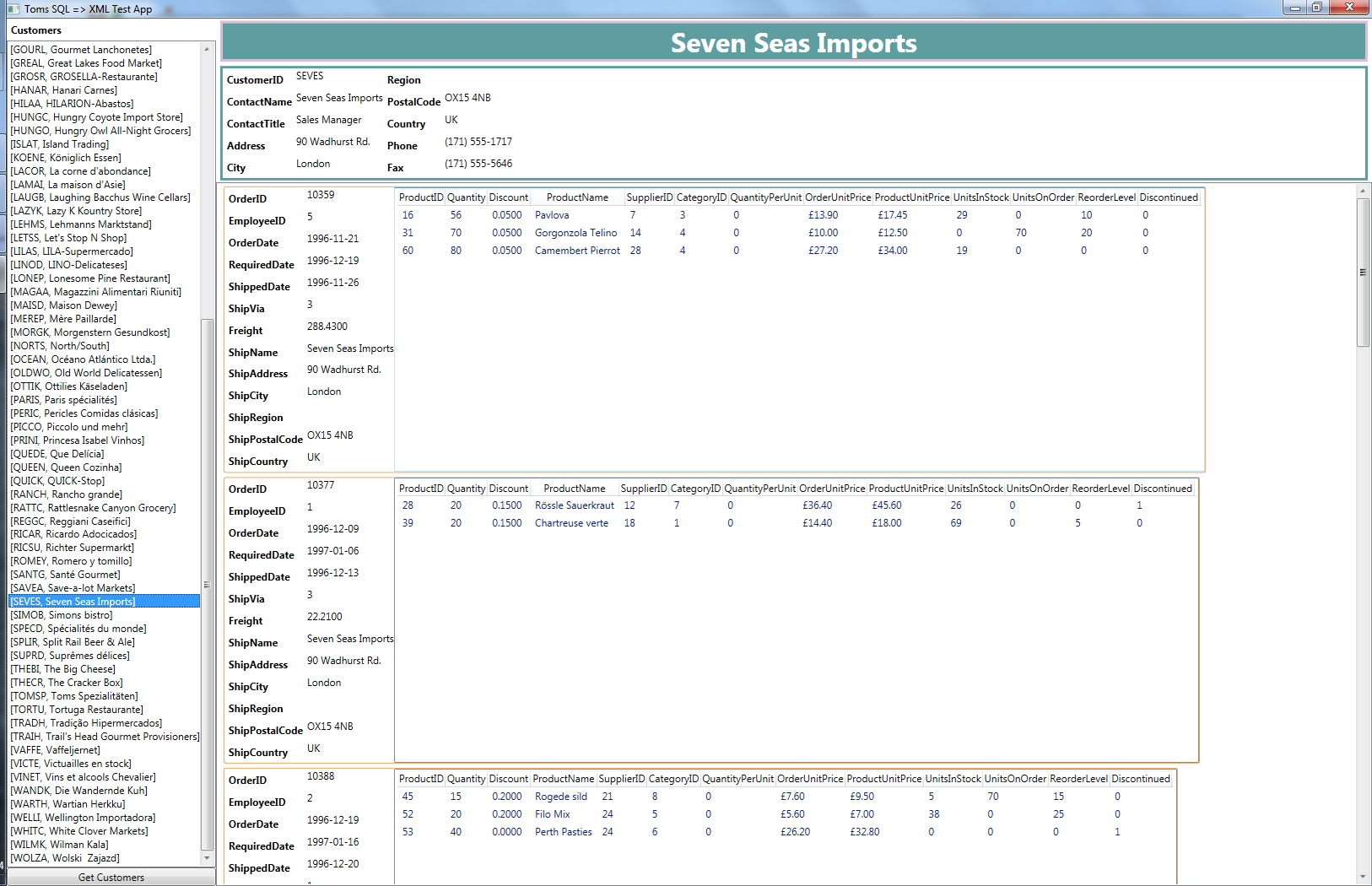
What I did with the above was to bring it back straight into a WPF GUI and use WPF’s ability to databind directly to XML. Then curiosity got the better of me. I copied the app and produced a version that was almost identical, but used Linq-to-Sql and bound directly to the object model.
SQL to XML Example App
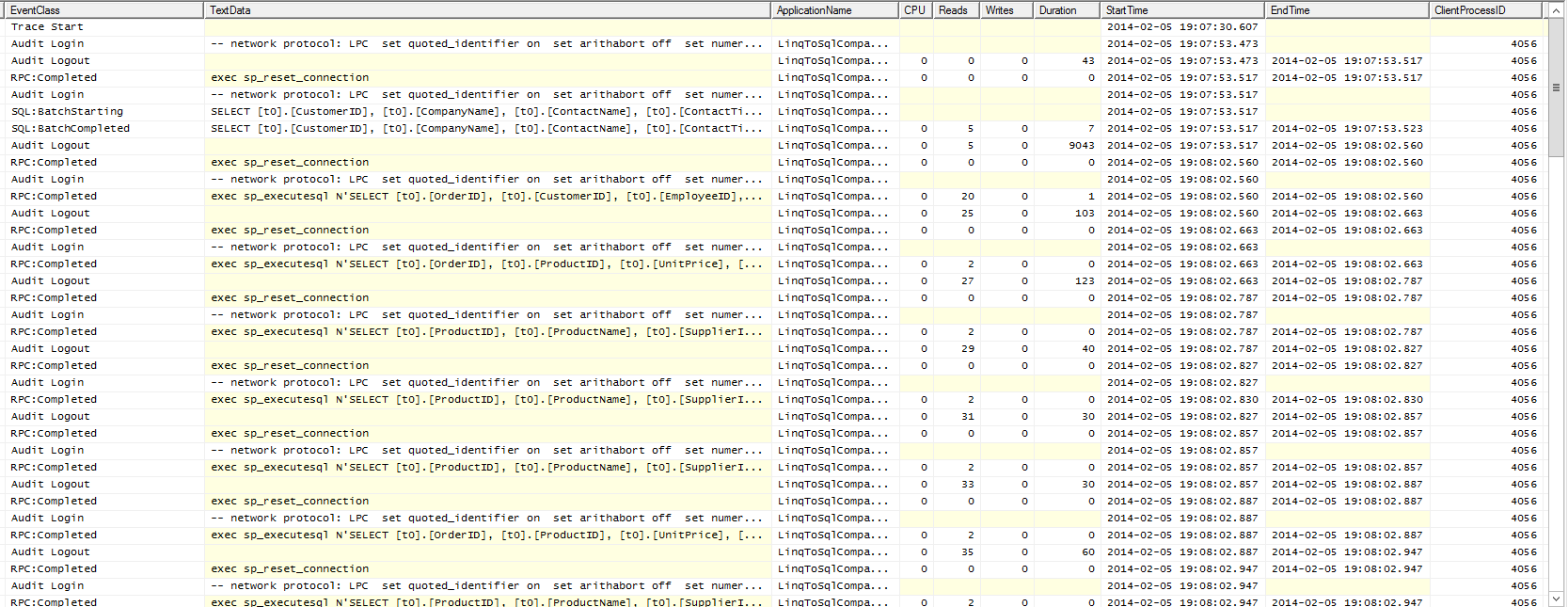
In use there doesn’t appear to be too much difference between them. I think the XML version is slightly faster but I accept that I may be biased. We’re dealing with a very small data set on a local server however so it’s not really surprising that there’s no immediately obvious difference. To get some results we have to look at SQL Server Profiler.
So I made sure that I did the same repeatable action – I first loaded a list of all the customers and then I selected just one customer, Seven Seas, for display. The differences are remarkable.
Profile of Data Retrieval Using XML
SQL Server Profiler of XML Retrieval
Profile of Data Retrieval Using LINQ
SQL Profile of LINQ Retrieval
What we can see here is Linq-To-Sql issuing a rash of tiny queries to pick up lots of individual pieces of information.
Conclusion
The real conclusion is that I probably didn’t pick a great example. It’s clear however that the approach of Linq-to-Sql and my XML based method are polar opposites, the former hitting Sql Server with a rash of small queries, the latter with fewer, much larger ones. Even on local servers round trips cost and I suspect that as the number of users increased and the size of the data increased the performance of the Linq-to-Sql version would start dipping much faster than that of the XML based version.
In the production environment I tend to use multiple result sets because it generally works out cheap to rejoin them on the client side. It’s nice to know however that XML is sitting there in my back pocket, giving me an alternative.
Reading Time: 4minutesTweetcaster spam
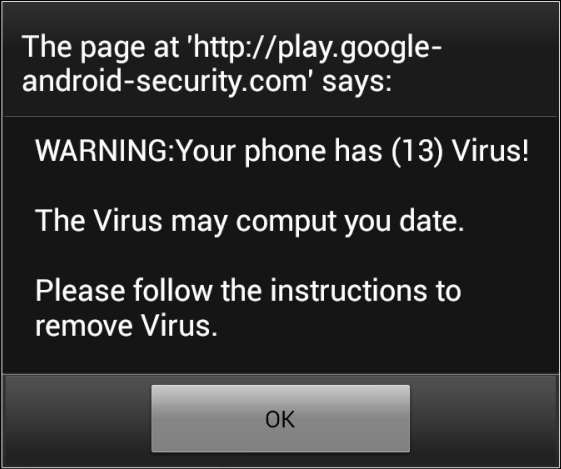
It appears that Tweetcaster has just become Spamcaster – it threw a message up on my phone telling me that I had 13 Virus[sic]. I deleted the application immediately and as a precaution checked that it was the only application from “One Louder Apps” that I had.
I’m very disappointed with “One Louder Apps”. I appreciate that all software houses have to make money (hell, we do) and I’m fine with that. I’m fine with free apps being supported by advertising. What I’m not fine with is allowing an application to be hijacked by a con. My phone does not have any viruses and the site / software I was being linked to would almost certainly install malware rather than removing it.
Anyway enough ranting. This got me thinking though about some of the less desirable near inevitabilities of app development.
In the software industry we love the app stores because the barriers to entry to this market are small. You don’t need to be a huge software house with massive resources to write some really clever and useful apps.
There’s a flip side to this coin though, if the barriers to entry for you are low then the barriers to entry for your competitors are also low. Consider the following (rather simplified) story.
You and a mate have a really cool idea for an app. You start coding it in your spare time and release an early version to the market place. It starts getting noticed. At the same time it’s noticed by customers it’s also noticed by potential competitors. They start designing similar apps, ones that have all the features yours does and a few more on top, but it’ll be a while before they get to market. So you have a golden window to make your app the best you can and get the cash in before there’s any real competition.
You’re making a bit of money out of it now though which means you can hire a couple of extra coders. So you all start hacking in features as fast as you can and the app rises in the charts, the revenue rises and everything is looking good. You buy a Porsche.
The code is suffering however from all the hacking and soon you notice that you’re having to do a lot of rework to add a feature. What’s more when you add a new person to the team your output doesn’t seem to increase by one person’s worth, more like half of a person. This is because you’re finding that you’re having to introduce procedures for things, and do documentation and all that overhead that you didn’t have to do when it was just 2 of you. But hey, the money’s flowing in, everything is rosy.
No actually, because if at this point you’re not well on the way to implementing the next killer feature then you’re screwed. Those apps that were designed after yours came to market are going to start coming online. What’s more because they designed in features that you had to hack in later they’re going to be more swish and because their code is still fresh they’re going to be able to implement new features with much less effort than you.
Even if you have got that next feature lined up you’re still in a race that you’re unlikely to win in the log run. You can’t recover your initial velocity, it’s just not possible with a hacked-to-bits code base. It’s always going to cost you more to develop anything than the newcomers to the market. With revenue falling as your market share decreases you can’t afford to throw enough people at the project to brute-force your way back to the top.
Unless you can find some way of drastically increasing your income stream it’s time to put your head between your legs and kiss your Porsche goodbye.
It’s not all doom and gloom though, there are a few ways you can combat this. Not every app / software house crashes and burns quite so pathetically.
For games especially you can release alternative versions – “in space”, “Star Wars edition” etc. that are basically the same code with a few visual tweaks. I could name several game franchises that have been able to do this very well indeed. You can even release “new” games that are substantially the same code as the old and hence don’t need that much development.
If you can use the ascent and some of the initial revenue of the first application to get a second one off the ground then as long as you keep having good ideas for apps you can keep a flow of applications. As one dies the next will become your major revenue earner.
If you use more formal development techniques from day 1 then you’re never really going to have that big burst of activity in the early phase but you’ll be able to build on what you’ve done and maintain your velocity. Competitors will come and go, your app will fluctuate in the marketplace but you stand a reasonable chance of keeping it near the top for a long period of time.
It’s quite fun to look at the successful apps and app developers in the market place and try to work out which they’re doing. Clearly the likes of Microsoft, Google, Facebook etc. are so big they’re largely irrelevant. They need to have the apps, they don’t necessarily need to make money directly from them and they can hurl seemingly unlimited resources at them if needs be.
Most of the smaller firms though you can see quite clearly what their business strategy is.