The Same Thing We Do Every Night, Pinky - Try To Take Over The World!
Tom Fosdick
Tom Fosdick is a software architect whose experience ranges from low level coding through to product management, delivery and customer relationships.
For nearly 20 years Tom has specialised in providing advanced technology to front line Emergency Services both in the UK and internationally.
#if DEBUG
DumpCallStack();
#else
#error REMOVE BEFORE RELEASE - Tom added this looking for bug 1223
#endif
You Really Don’t Want To Upset Her…
Why on earth would anyone want to do that? Well sometimes when you’re looking for a bug you add either debugging code or experimental code that you think might fix the issue. This code is often not of production quality. Then you find the actual bug and it’s nowhere near the new code, or you have to go off and do something else. You then forget about the code that you’ve added, it gets checked in and eventually makes it out into a release. Then you end up with Ariane 5 when it hits the customer site…
So why not just wrap it in #if DEBUG?
There are 2 reasons;
Because over time you end up with a hell of a lot of #if DEBUG and your actual code gets difficult to read.
More importantly because your debug version starts to radically depart from the release version. Consider the above – generating a stack trace is a relatively expensive operation and ultimately this writes it to a file. This quite substantially alters the way the timings in the code and the write to file has some (limited) synchronisation effects. This could actually mask problems.
Ultimately the more similar the debug version is to the release version the maintainable the code is and the more chance there is of a problem being spotted before the code gets to the customer. Experimental code and any form of debug code that could cause the debug version to function significantly differently to the release version should be removed.
SEED Software is fairly heavily Microsoft orientated. It’s no secret that I’m a fan of Linux, indeed I started my career as a *nix developer. In 2000 though I was looking for my next career move and there just weren’t enough opportunities in the *nix world, so I jumped ship and became a Windows developer. Since then Linux has had to take a back seat.
However I recently ordered a new NAS and a Raspberry Pi. This means that I currently have;
An Android smartphone (HTC Wildfire S running Cyanogen)
A (Linux based) ADSL router
A backup (Linux based) ADSL router
A (Linux Based) NAS
A Raspberry Pi
For the first time since 2000 I have got as many Linux machines as I have Windows, possibly more as there are other pieces of hardware that I have which could also be Linux based – I’m looking suspiciously at my TV for starters…
The downside of all this is that I think I may have just blown any pretence I might have had that I am not a geek. Hom hum, I can live with that!
We’ve all visited the temple of the Great God Rebootus – praying that a magic key sequence or just turning it off and back on again will solve our problem.
When my boiler stopped working last night though the Great God Rebootus didn’t come through for me. So before I phoned the plumber I thought I’d just give another ancient ritual a shot – it works surprisingly often.
It’s called Reseatum Konnectorum – the basic procedure is to unplug and reconnect every connector you can find. Corrosion, vibration, there are all sorts of reasons why something that was once a good connection can go bad. It’s well worth giving it a shot, especially when you’re facing a big bill just for calling someone out to look at it.
So I now have a working boiler again. Fingers crossed it will continue to do so!
I’ve stopped Google from caching this blog, it’s the only logical option.
Things change, circumstances change, events happen, our opinions change. The web though appears timeless, an article written 10 years ago can easily crop up in a search today and nobody reads the date. The advice that one might have given 10 years ago however may be entirely contradictory to the advice one would give today. The opinions expressed before the current recession may be entirely at odds with today’s. The conclusion we inevitably come to is that being able to edit and delete an article is really rather important.
Not only this but from a purely selfish point of view we might need to delete or edit articles – imagine writing an article that praised a particular company only to find out later that your own company was being taken over by one of their competitors. If the first time your new managers hear of you it’s because someone is telling them you’ve written an article supporting the opposition that stain is going to be difficult to remove from your reputation.
Articles can hang around in caches for a very long time after they’ve been taken down or edited on the original site. I’ve found myself writing articles and not publishing them simply because of this – I think to myself that I may change my mind about the subject at some point, or that the article is pertinent only to the world that exists today. So it’s a no-brainer for me and I would suggest any blogger, if you want to say anything that you may ever have cause to change or delete later, you have to try to stop it being cached.
My television offended me last night. No, not a television programme the actual TV. We haven’t quite got the networking in the house finished so I put a video file I onto a memory stick and shoved it into the telly’s USB port.
“Invalid File Format”
It told me. So I fetched a laptop, plugged that into a spare HDMI port and guess what – it played the file fine.
This may seem like a trivial issue but it does highlight just how exposed we as programmers are to the user. Errors are a particular area of concern because the marketing people will agonise for hours about exactly what the splash screen should look like, but they rarely have any input at all on what error messages should say.
Being able to provide the user with error messages that are useful and informative can greatly improve the user perception of the product – so when you’re writing error messages just have a think about how a user will react if they see it. Exception.ToString() might not be terribly useful to them, for instance.
Power cut!Beautiful design is great, but more often than not it doesn’t pay the bills. Pragmatism is one of the things I try to instil in the SEED students. There’s a time for complicated diagrams with lots of lines and boxes, there’s a time to elegantly partition the layers, but there’s also a time to ‘it it wiv an ‘ammer.
I was recently dealing with some simple comms routing. I needed to store information about an address composed of 3 parts;
Sector – a byte in storage this identifies the organisation to send the message to.
Node – 10 bits denoting the unit to send to, e.g a Fire Station or Fire Appliance (Engine)
Port – a byte indicating the application to send to, e.g. the printer
The information that I needed to associate with this address was actually an email address that it translated to. So it’s an obvious tree structure, right? What’s more you can use an XmlSerializer to save and load the relationships – this is important because it needs to be maintained by a human. So let’s look at the XML.
Oh dear, that’s not very good. There could easily be a couple of hundred entries which would mean that the sector you’re editing might not be in view, similarly the node. It’s all a bit untidy really.
Also lookup isn’t simple, you need to do it in 3 stages, find the Sector, then find the Node, then find the Port. So the XML is untidy and the code is untidy. But the design is good, yes?
There’s a better way. I realised that 8 bits + 10 bits + 8 bits is 26 bits and a standard csharp integer is 32 bits. So we can just have one object that has Sector, Node and Port properties but has a "lookup" value that is an int and is made up from the parts of the address.
[XmlElement]
public class AddressRelation
{
[XmlAttribute]
public byte Sector { get; set; }
[XmlAttribute]
public short Node { get; set; }
[XmlAttribute]
public byte Port { get; set; }
[XmlAttribute]
public string EmailAddress { get; set; }
//so that we can get a lookup code, for comparison
public static int GetLookupCode(byte Sector,short Node,byte Port)
{
return Sector << 24 | Node << 8 | Port;
}
public int GetLookupCode()
{
return AddressRelation.GetLookupCode(Sector, Node, Port);
}
//this makes serialization much easier
public static AddressRelation CreateFromLookupCode(int LookupCode,string email)
{
return new AddressRelation()
{ Sector = (byte)(LookupCode >> 24),
Node = (short)((LookupCode >> 8) | 0xffff),
Port = (byte)(LookupCode | 0xff) };
}
}
That’s great. When we call “GetLookupCode()” we get an int that uniquely represents that address. We can easily compare that with other objects. Note that I didn’t override GetHashCode() or the equality operator because although the addresses might be the same, the emails may be different.
If you’re wondering what >> and << do then you need to look up bit shifting and bit masking…
They serialize nicely, too.
But how do we use it? Well actually the easiest thing to do is to load it into a dictionary, which should make the uses of some of the extra methods in the data class clearer…
[Serializable]
[XmlRoot(Namespace = "www.tomfosdick.com/blogstuff",
ElementName = "AddressStore",
IsNullable = true)]
public class AddressLookup2
{
[XmlArray("AddressRelations")]
public AddressRelation[] AddressRelations
{
get
{
return addressLookup
.Select(x => AddressRelation.CreateFromLookupCode(x.Key, x.Value))
.ToArray();
}
set
{
addressLookup = value
.ToDictionary(k => k.GetLookupCode(), v => v.EmailAddress);
}
}
private Dictionary<int, string> addressLookup = new Dictionary<int,string>();
public string GetAddress(byte sector, short node, byte port)
{
string result;
if(addressLookup.TryGetValue(AddressRelation.GetLookupCode(sector, node, port),out result))
return result;
return null;
}
}
The advantage of using a Dictionary here and of the way I’ve shuffled the parts of the address into an int means that this will always be serialized in order, Sector most significant then Node then Port. So editing the XML by human hand will be easy – even if one is added out of sequence when the file is next machine written it will be sorted again.
The code is neat, concise and fast. The design is a bit mucky, it’s not clean and elegant but in all other ways – some of which are far more important than the cleanliness of design – this wins.
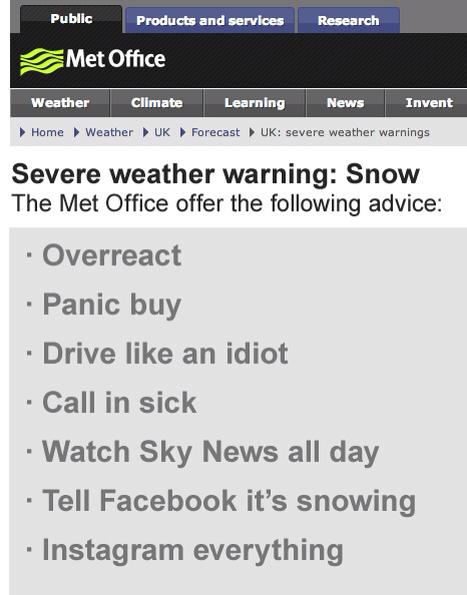
What to do in snow [image credits unknown]Why does Britain – particularly England – grind to a halt at the first flake of snow?
Some of it, of course, is down to people being pathetic but the fundamental reason is clear – we’re just not set up for it. However one has to question whether we should be. Snowfall in the UK varies wildly depending on where you are but it’s a rare year that we have more than 2 weeks which are seriously disrupted by snow – 3.8% of the year. How much do we really want to invest in such a small percentage of our time?
Other (similar) countries don’t grind to halt because they have enough snow to make investment worthwhile. Finland is under snow, depending on where you are, for between 3 and 6 months of the year.
To make this clear we’ll look at some of the cheaper and reasonable precautions one can take.
Get some long life / tinned / frozen food in.
Make sure you have a good supply of fuel – wood, coal, gas, oil etc.
Most people have a garden spade, it’s useful to have one in the car (whether this be the garden spade or a “travel shovel” specifically for the car).
Carry a couple of pieces of old carpet and perhaps planks of wood in the car. Maybe even specialist grip mats.
Make sure your screen wash is full and mixed up correctly for winter. You can buy concentrated screen wash at good motor factors, mix it up as per the instructions for winter.
Make sure you have proper boots that can cope with snow (good wellies will suffice).
Get some grit-salt in for your path and/or drive. It’s not expensive. You can use dishwasher salt or even table salt but they tend not to come in big bags for a couple of quid. If you haven’t got (enough) salt then sand, grit or even ash will help. It freezes into the surface making compacted snow more grippy.
These reasonable precautions won’t cost much. Motorists in Scandinavia however use Winter tyres. Even if you have a modest car that’s £300 and unless you’re going to pay someone to change them twice a year you can add the cost of a second set of wheels to that.
What’s more unless you do a lot of miles the tyres will probably perish before they run out of tread which just wastes money. They do make a real difference to driving on snow (in fact they have specific snow tyres in Scandinavia which are even better). For 4% of the year though where they make that real difference is it worth it?
That’s one simple investment we could make in our own cars but it highlights the issue rather well. Similar disproportionate investment would be required in much of our infrastructure if we were going to just carry on as normal in the snow in the same way that Scandinavian countries do. For 4% of the year it’s simply not worth us making those investments. It’s actually more cost effective for us to just to do the best we can with the limited resources available.
The key to dealing with snow in the UK is planning. We know it’s going to happen for a few days a year and the weather forecasters are rarely caught out by it, so plan in advance. Businesses should also be aware of the problems and should have plans. It’s all common sense.
Reading Time: < 1minuteSomeone’s changed more than the wipers…
UK motor factors Halfords are running adverts for their new “We Fit” service and I absolutely hate them. There’s one common message – that even the most basic of car maintenance tasks is beyond the ability of the average motorist. This annoys me intensely because I firmly believe that every motorist should be capable of such simple tasks as changing bulbs and windscreen wipers – it’s part of understanding the vehicle that you’re driving. What’s more these things aren’t difficult. They require very little actual skill, just care and attention to detail.
However there’s a calmer part of my mind that says these adverts are actually good. I’ve seen the results when people thought they knew what they doing too many times and some of them have been pretty horrendous. Now I know that large chains don’t have best reputation for quality of workmanship but I’d still rather that vehicles using our highways were maintained by someone who’d had some form of training. That way there’s slightly more chance that the oncoming light in the freezing fog is actually a motorcyclist, not a car with only one light working.
This is my mousemat. It’s about the same age as many of our students and it’s pretty much the only piece of computing technology from 1993 that’s still relevant today.
The 3.5 inch floppy was the standard way of supplying data and even software. Windows came on 6 to 8 of them depending on the edition.
Mice used to use a ball and rollers to track movement. They’re now optical.
Only cheap keyboards used membranes. Good ones were mechanical (switch) keyboards. These are now almost impossible to get hold of.
USB was unheard of. Peripherals either had to connect via an existing serial or parallel port or use their own interface card.
The Compact Disc was common, but the CD-ROM had not yet entered the world of computing (let alone DVD or recordable technology).
Monitors used Cathode Ray Tubes. This made anything bigger than 19″ heavy, awkward and expensive. If the office heating failed though they were good for that.
A myriad of interfaces have come and gone. ISA bus, VESA local bus, DIN style keyboard connections, PS/2, IDE, etc. etc.
There are a few things that haven’at changed that much.
Hard disks – the mechanical type – still use much the same physical technology. The data capacity now though is astounding. A “big” HDD in 1992 was 20Mb. It’s now 50,000 times that.
VGA was the latest and greatest in 1992. We still use it today, mainly for projectors although even this is fading in favour of DVI / HDMI.
Cases are still made of cheap steel and PSUs are still cheap switch-mode devices that fail every more often than any other component.
Having said all this it’s not so long ago I lifted the lid on a piece of equipment that had just been decommissioned from a fire service. I recognised the CPU instantly, it was a Zilog Z80 in a DIL40 package, placing its vintage firmly in the 1980s and possibly as early as 1976.
So the power company decided to schedule a 9 hour outage for today and not bother telling us. At 09:15 the power went off and we were suddenly in the dark. No power, no network and even the cordless house phone was off. Sure we have mobiles but we live in a dip and have minimal signal.
We’re screwed, right?
Not at all, because when I became a remote worker I spent some time working out exactly what I’d do if this happened. Dress this up in fancy clothes and a consultant will call it “disaster recovery planning” and relieve you of the contents of your wallet. The reality is that it’s just a bit of common sense, but it is important that any small business actually does it.
There’s an old phone I keep in the spare bedroom that doesn’t need external power so within a couple of minutes we have some form of communication. All the utility company phone numbers are on a board by the fridge so within 10 minutes I want someone’s head on a plate. At least I know the score though and it means we’re out of the office for the day. We both use (docked) laptops as our primary machines so we grab them, an external HDD and a bunch of other goodies and decamp to a nearby relative’s. All sorted.
If you are a small business, a remote / home worker or a contractor you need to think about what you’d do if something goes wrong. There are four things to look at.
What can go wrong?
How likely is it?
How severe it it?
What are you going to do about it?
There are 2 parts to the last one. One part is obvious, what you do when it happens but you should also consider how you can mitigate it – how you can make it less likely or its effect less serious if it does happen.
Oh, and a small piece of advice, always get the most efficient freezer you can. 9 hours of no power and not a hint of defrosting!