Tom Fosdick is a software architect whose experience ranges from low level coding through to product management, delivery and customer relationships.
For nearly 20 years Tom has specialised in providing advanced technology to front line Emergency Services both in the UK and internationally.
It’s no secret that I am not an ORM fan. Actually that’s a little harsh, ORMs bring some significant advantages and it’s not just having an object orientated view of a database – a lot of junior developers just don’t know SQL and they can save a massive amount of development time. They also discourage people from infecting the code-base with SQL which can prove a real maintenance headache. So in many ways ORMs are a good thing.
Unfortunately using an ORM can result in serious database abuse. Not so long ago I profiled some of the LINQ-to-SQL that one of our products uses and I nearly had kittens (some of that’s mentioned in this article). It was making thousands of unnecessary round trips to SQL Server to pick up individual records when one query could have got everything we needed.
A project that my team have just inherited demonstrates a different kind of database abuse rather neatly. There’s a web service that basically just provides a view of the DB. One of the methods does this…
Which is fine, apart from the fact that it transpires that it’s perfectly legitimate to have duplicate keys in the database (it’s not our DB). The Web Service is consumed by our remote client and we’d rather not be sending that any duplicates – so I modified the LINQ to eliminate them. The situation is slightly more complex than just using .Distinct() because in the case of duplicates what we actually want is the later record, according to the Added datetime field.
The .GroupBy groups the records by the key, then the following select only returns one record, the one with the highest “Added”. The result of this is an IEnumberable<Street> so the .OrderBy etc. will work just fine. It doesn’t work though, it throws a SQLException because the SQL that the Entity Framework generates contains the “Added” column in the order by clause twice. So I thought I’d profile the SQL Server an see exactly what it was trying to do…
SELECT TOP (500) [t4].[test], [t4].[GUID], [t4].[ParishGUID], [t4].[Name], [t4].[Active], [t4].[Added], [t4].[Created]
FROM (
SELECT [t1].[value]
FROM (
SELECT UPPER([t0].[GUID]) AS [value]
FROM [dbo].[Street] AS [t0]
) AS [t1]
GROUP BY [t1].[value]
) AS [t2]
OUTER APPLY (
SELECT TOP (1) 1 AS [test], [t3].[GUID], [t3].[ParishGUID], [t3].[Name], [t3].[Active], [t3].[Added], [t3].[Created]
FROM [dbo].[Street] AS [t3]
WHERE (([t2].[value] IS NULL) AND (UPPER([t3].[GUID]) IS NULL)) OR (([t2].[value] IS NOT NULL) AND (UPPER([t3].[GUID]) IS NOT NULL) AND ([t2].[value] = UPPER([t3].[GUID])))
ORDER BY [t3].[Added] DESC
) AS [t4]
ORDER BY [t4].[Added], UPPER([t4].[GUID]) DESC, [t4].[Added] DESC
Holy Truffle Oil Batman! That’s bonkers! What makes matters worse is that even if I correct the SQL the query times out and there are only 30,000 records in the DB. Because it’s bonkers.
So I started to think about how I’d actually do it in SQL. This is my first attempt, now I’m not saying it’s optimal. I think there may be ways I could improve it but it works and with 30,000 records it returns pretty much instantly.
SELECT [GUID]
,[ParishGUID]
,[Name]
,[Active]
,[Added]
,[Created]
FROM
(SELECT *, ROW_NUMBER() OVER(ORDER BY [GUID]) RN FROM
(SELECT *
,RANK() OVER (PARTITION BY [GUID] ORDER BY Added,NEWID()) RK
FROM dbo.Street
WHERE @takeAll = 1 OR Added >= @added) DEDUPE
WHERE RK=1) CHUNK
WHERE RN > @start and RN <= @start+@take
The Entity Framework is kind enough to provide a generic ExecuteQuery<T> method on the DataContext so I’ll be writing a new method in the DAL effectively to override Entity Framework’s toxic SQL generation in this case. I suspect my new method won’t be lonely for long.
Reading Time: 2minutesOne thing about C# style that I get asked quite a lot is why I tend to write if statements like this…
if (null != args)
{
It’s not how most people think. It seems far more logical written this way round…
if (args != null)
{
It’s actually a hang-on from my days as a plain old C developer, most of the time it’s not relevant to C# but there’s one particular instance where it is.
bool someBoolean = false;
bool someOtherBoolean = true;
if(someBoolean = someOtherBoolean)
{
Console.WriteLine("The if condition evaluated to true!");
}
Console.WriteLine(String.Format("someBoolean is [{0}], someOtherBoolean is [{1}]", someBoolean, someOtherBoolean));
So when we run this, we might not get the result we expect.
This is because in C# assignment operations have a result. Instead of comparing the two items in the if statement (==) we assigned the value in someOtherBoolean to someBoolean (=). Basically we just used = where we should have used ==, it’s an easy mistake to make and in this instance it compiles and runs, it just doesn’t do what we want, at all…
I actually wrote about this in an article some time ago, but back then I was talking about doing it deliberately, and as part of a work of extreme evil.
OK, so that’s a convoluted example and in reality you’re unlikely to cause yourself serious problems in C# because C# is very strict about the result of whatever’s in an if statement being Boolean. So if you did accidentally write this, it wouldn’t compile.
if(someObject = null)
{
someObject = new someType();
}
This is because the result of assigning null to someObject is null, which is not a Boolean.
However in C the equivalent will compile and will run. In C anything that evaluates to zero is treated as false and anything that evaluates to non-zero is treated as true.
This will crash every time, because we’re actually assigning NULL to the value someStruct. The result of that assignment is zero, which evaluates to false, so execution skips the contents of the if statement and goes directly to where the structure is accessed – the structure that we’ve just assigned to NULL.
This is my mobile phone, or cellphone if you will. It’s a HTC Wildfire S running cyanogenmod 9. Sure it was never an expensive phone but I didn’t get it because it was cheap, I got it because it was small.
I am notoriously hard on kit. Something like a mobile phone just gets shoved in my pocket and ends up doing whatever I do. Scaling roofs to find mobile phone signal is perfectly normal in my world, as is climbing into the loft, crawling into tight gaps and running out in a howling gale to rope the remains of the fence to something a little more stable.
Amongst my friends, many of whom have the same attitude to life as me, there is a catalog of broken phone screens. My little Wildfire S has lasted a few years now without any serious damage.
It is however getting a little long in the tooth. It never had even remotely enough memory to start with and fiddling it to make it think that a portion of the SD Card is actually internal memory isn’t the most reliable. It’s also suffering a bit with a lot of modern apps which are a getting a bit slow.
So I’m in the market for a replacement – I figured this should be easy as there are a lot of new “mini” phones on the market. Only they’re not, the new “mini” phones are only mini compared to their tablet-size counterparts.
The look of horrible confusion on the face of a mobile phone stores salesperson is one I’ve got well used to, “sorry, I’ll just repeat that. I’m looking for a small, tough smartphone. Not a 6 inch mini-tablet that will break as soon as I attempt to climb a ladder with it in my pocket.”
I’m never far from a PC, a laptop or a tablet. I don’t need a mobile mini-tablet, what I need is a smart-phone, something that fits in my pocket and allows me to check social media and run a few tracking and navigation apps and maybe listen to Buddy Guy.
Reading Time: < 1minuteActual Bread! From My Oven!
It’s not a big thing, especially considering all the culinary adventures I’ve had, but up until 7pm this evening at no point in my life had I ever attempted to bake bread. Those two mini-loaves on the right are my first ever attempt and not only do they look like bread they actually taste like bread too!
As a child I was fascinated by how my mother would mix the dough and kneed it. Then the magic started – the dough would rise. Then she’d bake it and we’d have bread. My mother made bread, wonderful smelling soft bread. Most people had to buy bread, but my mother could make it. To my child’s brain that was very impressive.
This probably explains why I’ve been entirely happy to undertake some ludicrously complex and technical culinary challenges but to date not bread baking. I was scared. I was scared that I might not be able to do it and that if it didn’t work it would ruin the memory of that smell. It would ruin part of my childhood.
But it did work, and actually to me it’s quite a big thing.
Reading Time: 7minutesRound trips to SQL Server kill performance. It takes time to set up the command, get it to the SQL Server, then to parse it, search for and format the results then return them to the application. If you need lots of little pieces of information this can get extremely frustrating, especially when you get a call from your DBA about the “horrible” app that you’re developing.
Sometimes you can bring back a super-set of the data you need in one query rather than several smaller queries and you may find that filtering the data down to what you need in code is faster than hitting SQL Server with lots of small queries. It is subjective, of course. There’s always a level in database programming where the theory is fine but you don’t really know until you try it.
I found myself thinking that there must be a better way though. There are two scenarios I want to cover – let’s start with the simpler one.
My Selection Criteria is Complex – e.g. It Contains a List
Wanting to pass a list as an input parameter to SQL Server is a common problem, and one that I’m pleased to say Microsoft addressed in SQL Server 2005 with table valued parameters. Except that they didn’t implement it in Linq-to-Sql or Entity Framework which proves a bit of a headache.
Table valued parameters also need to be in the schema and that’s not always under the control of the app developer. So what do you do if you’re stuck in hard place where you can’t do it the right way?
Let’s say Northwind – Microsoft’s now ancient example company – was integrating to another system. That other system might want details of several customers. Helpfully they can provide us list of the IDs they require. This is easy if you’re typing the SQL in directly…
SELECT * FROM dbo.Customers WHERE CustomerID IN ('BERGS','GODOS','FURIB','GREAL')
You can of course build up the query text in code to be just like the above but you’d better pray that “Little Bobby Tables” never becomes a customer.
Naturally you can use a stored procedure to parse a CSV type string but whilst that’s not so open to a Sql injection attack it’s still pretty fragile.
A more robust way is to use XML. Here’s some C# with everything hardcoded so, as long as you have a Northwind somewhere, this should work via the magic of cut-and-paste (and editing the connection string).
private void GetCustomersByID(List<string> list)
{
//make an XML document listing the customer IDs
XElement doc = new XElement("customers");
list.ForEach(customer =>
doc.Add(new XElement("customer", new XAttribute("CustomerID", customer))));
//Connect to the SQL Server
using (SqlConnection connection = new SqlConnection(@"Server=(localdb)\v11.0;Integrated Security=true;Initial Catalog=Northwind"))
{
connection.Open();
using (SqlCommand getCustomers = connection.CreateCommand())
{
getCustomers.CommandType = System.Data.CommandType.Text;
//Command text uses the XML document to join to the target table as a way of selecting rows
//(there are other, probably better ways)
getCustomers.CommandText =
"DECLARE @hdoc INT " +
"EXEC sp_xml_preparedocument @hdoc OUTPUT, @xml " +
"SELECT [dbo].[Customers].[CustomerID], [CompanyName], [ContactName], [ContactTitle], [Address], [City], " +
"[Region], [PostalCode], [Country], [Phone], [Fax] FROM [dbo].[Customers]" +
"INNER JOIN OPENXML(@hdoc,'/customers/customer',1) WITH (CustomerID nchar(5)) req " +
"ON req.CustomerID = dbo.Customers.CustomerID " +
"exec sp_xml_removedocument @hdoc";
getCustomers.Parameters.AddWithValue("@xml", doc.ToString());
//bring the results back and display them
using (SqlDataReader resultsReader = getCustomers.ExecuteReader())
{
while (resultsReader.Read())
{
object[] values = new object[resultsReader.FieldCount];
resultsReader.GetValues(values);
Console.WriteLine(String.Join(", ", values.Select(x => x.ToString())));
}
}
}
}
So we make an XML document in C# – there are any number of ways of doing this, I chose LINQ’s XElement – and passed it to the SQL Command as a parameter. We then use OPENXML to open it as a rowset and inner join it to the target table, allowing us to bring back only the rows we want.
Of course there is an overhead in constructing the XML and parsing it in SQL Server and we must be aware of that, but this little trick does allow one to neatly work around some quite common problems.
Of course this example is a little trivial. It’ really only to demonstrate a technique. Where XML particularly wins – even over Table Valued Parameters – is that XML does not need to be a list of the same type. You could even specify groups of parameters or a complex structure enabling the SQL Server to make some informed choices about the data to return without having to issue multiple queries and incur unnecessary round-trip overhead.
I Want to Return Complex Information Made From Many Fragments of Data
This usually manifests itself when you need data from several tables where there isn’t a one-to-one relationship.
If the relationship is simple sometimes it’s quickest to use a join and just throw away the duplicated sections of the row. e.g. you might want a the customer details and their 50 most recent orders – you can accomplish this with a join but you’ll get a copy of the customer’s details with every order details so that’ll be 49 copies of the customer’s details that you don’t need. It may be faster than using 2 separate queries.
You can also return multiple result sets from a query or stored procedure. Scott Gu covers that quite adequately in LINQ-to-SQL Part 6. In the above example you could return two result sets, one containing the customers and the other containing the orders. You’d then have to link them in code, but provided there aren’t too many rows this can be a quick option.
If it’s details of just one customer that you need you could return one result set (the orders) and use OUT parameters in the query – that’s another option.
I mention these options first because XML may not be the right way to go, I’m really just presenting it as an option that you could take. To that end let’s look again at the Northwind database – perhaps we want to bring back a lot of information about a customer, maybe the orders they’ve placed and what was in those orders. This is a hierarchical data set, of course we could do this with multiple result sets but we’d have to join them up on the client side and that could get messy. Instead we can use SQL Server’s ability to output XML. Of course batting XML around the place instead of nice binary types is going to incur a significant overhead and that should be taken into account, but there is potential here.
SELECT [CustomerID]
,[CompanyName]
,[ContactName]
,[ContactTitle]
,[Address]
,[City]
,[Region]
,[PostalCode]
,[Country]
,[Phone]
,[Fax]
,(SELECT [OrderID]
,[CustomerID]
,[EmployeeID]
,[OrderDate]
,[RequiredDate]
,[ShippedDate]
,[ShipVia]
,[Freight]
,[ShipName]
,[ShipAddress]
,[ShipCity]
,[ShipRegion]
,[ShipPostalCode]
,[ShipCountry]
,(SELECT [OrderID]
,d.[ProductID]
,[Quantity]
,[Discount]
,[ProductName]
,[SupplierID]
,[CategoryID]
,[QuantityPerUnit]
,d.[UnitPrice] [OrderUnitPrice]
,p.[UnitPrice] [ProductUnitPrice]
,[UnitsInStock]
,[UnitsOnOrder]
,[ReorderLevel]
,[Discontinued]
FROM [dbo].[Products] p INNER JOIN [dbo].[Order Details] d ON p.ProductID=d.ProductID
WHERE d.OrderID=o.OrderId FOR XML PATH('OrderDetail'),ROOT('OrderDetails'),TYPE)
FROM [dbo].[Orders] o WHERE o.CustomerID=c.CustomerID FOR XML PATH('Order'),ROOT('Orders'),TYPE)
FROM [dbo].[Customers] c FOR XML PATH('Customer'),ROOT('Customers')
GO
The cunning bit here is using SQL Server’s subquery ability to produce a hierarchical XML dataset.
The root node is “Customers” containing multiple instances of “Customer”. Each Customer contains an “OrderDetails” element which is a list containing multiple instances of “OrderDetail”. This in turn has a “Products” element which is a list of “Product” items.
I won’t go into SQL Server’s ability to produce XML in any great deal suffice to say that it’s come a long way since 2005 and it’s now really quite powerful. I also accept that there may be better ways of achieving the above.
What I do need to mention is how to get this back to a C# app – don’t be tempted to use ExecuteScalar() – it will truncate long xml.
The following uses XmlReader which is in turn used with an XmlDocument. This is the asynchronous model which allows a little more responsiveness in the GUI, but does mean a lot of Dispatcher.Invoke().
What I did with the above was to bring it back straight into a WPF GUI and use WPF’s ability to databind directly to XML. Then curiosity got the better of me. I copied the app and produced a version that was almost identical, but used Linq-to-Sql and bound directly to the object model.
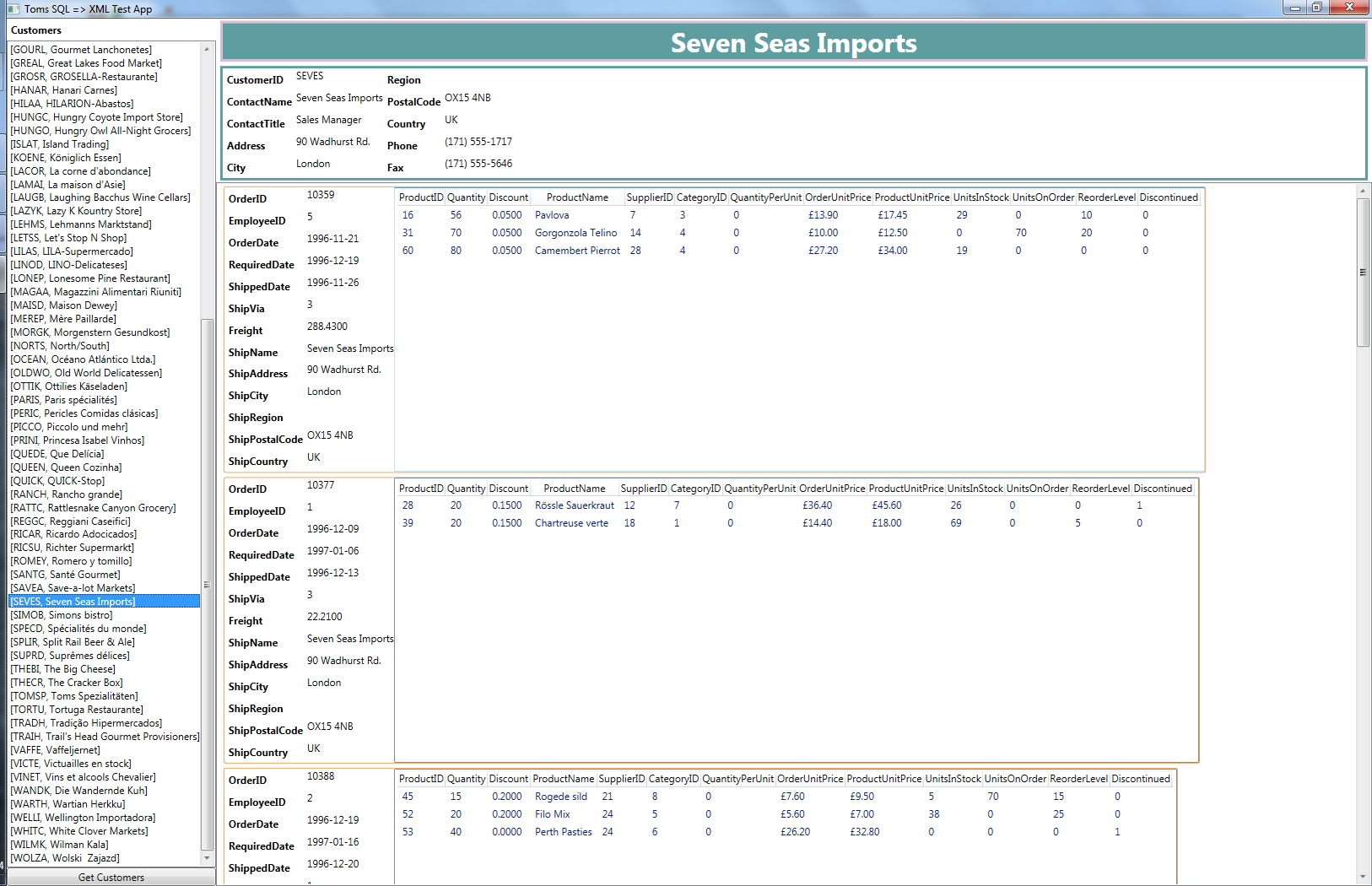
SQL to XML Example App
In use there doesn’t appear to be too much difference between them. I think the XML version is slightly faster but I accept that I may be biased. We’re dealing with a very small data set on a local server however so it’s not really surprising that there’s no immediately obvious difference. To get some results we have to look at SQL Server Profiler.
So I made sure that I did the same repeatable action – I first loaded a list of all the customers and then I selected just one customer, Seven Seas, for display. The differences are remarkable.
Profile of Data Retrieval Using XML
SQL Server Profiler of XML Retrieval
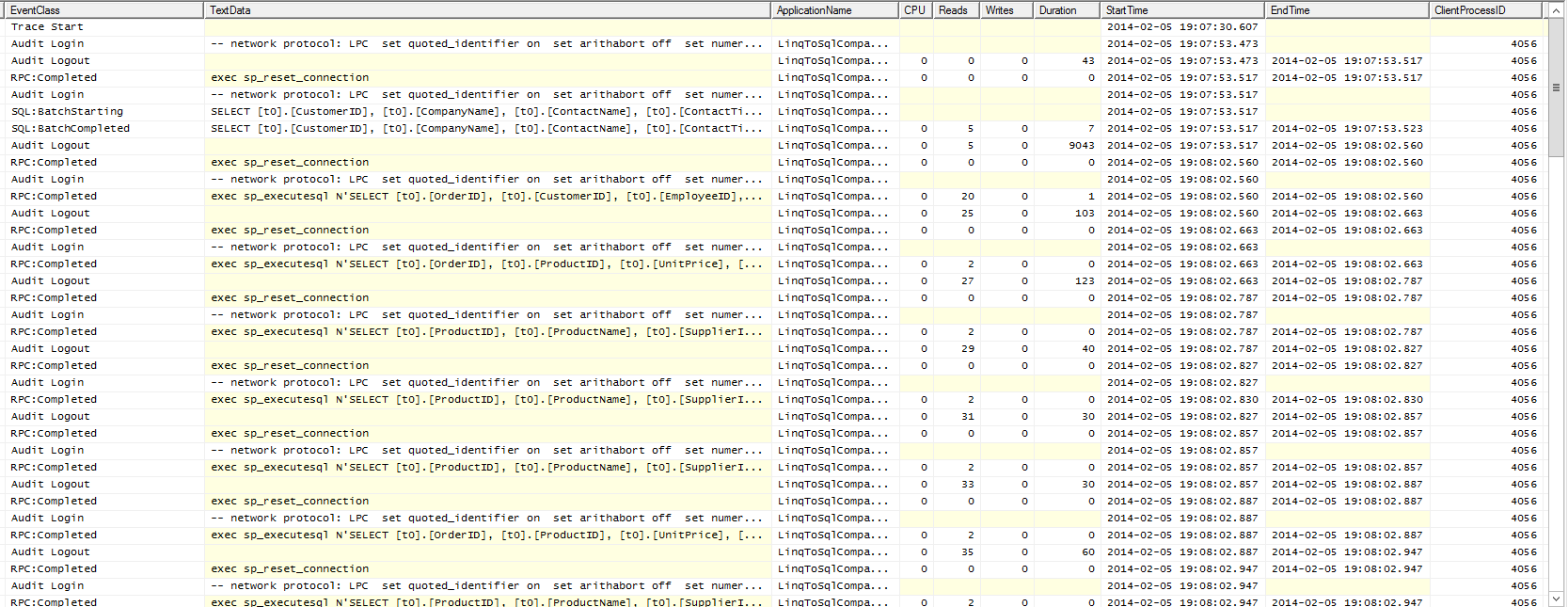
Profile of Data Retrieval Using LINQ
SQL Profile of LINQ Retrieval
What we can see here is Linq-To-Sql issuing a rash of tiny queries to pick up lots of individual pieces of information.
Conclusion
The real conclusion is that I probably didn’t pick a great example. It’s clear however that the approach of Linq-to-Sql and my XML based method are polar opposites, the former hitting Sql Server with a rash of small queries, the latter with fewer, much larger ones. Even on local servers round trips cost and I suspect that as the number of users increased and the size of the data increased the performance of the Linq-to-Sql version would start dipping much faster than that of the XML based version.
In the production environment I tend to use multiple result sets because it generally works out cheap to rejoin them on the client side. It’s nice to know however that XML is sitting there in my back pocket, giving me an alternative.
Reading Time: 4minutesTweetcaster spam
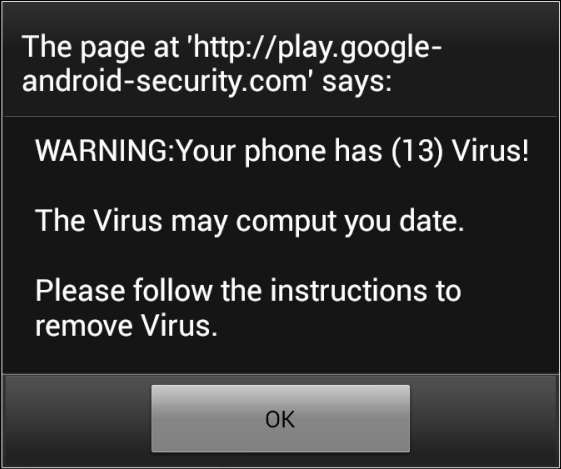
It appears that Tweetcaster has just become Spamcaster – it threw a message up on my phone telling me that I had 13 Virus[sic]. I deleted the application immediately and as a precaution checked that it was the only application from “One Louder Apps” that I had.
I’m very disappointed with “One Louder Apps”. I appreciate that all software houses have to make money (hell, we do) and I’m fine with that. I’m fine with free apps being supported by advertising. What I’m not fine with is allowing an application to be hijacked by a con. My phone does not have any viruses and the site / software I was being linked to would almost certainly install malware rather than removing it.
Anyway enough ranting. This got me thinking though about some of the less desirable near inevitabilities of app development.
In the software industry we love the app stores because the barriers to entry to this market are small. You don’t need to be a huge software house with massive resources to write some really clever and useful apps.
There’s a flip side to this coin though, if the barriers to entry for you are low then the barriers to entry for your competitors are also low. Consider the following (rather simplified) story.
You and a mate have a really cool idea for an app. You start coding it in your spare time and release an early version to the market place. It starts getting noticed. At the same time it’s noticed by customers it’s also noticed by potential competitors. They start designing similar apps, ones that have all the features yours does and a few more on top, but it’ll be a while before they get to market. So you have a golden window to make your app the best you can and get the cash in before there’s any real competition.
You’re making a bit of money out of it now though which means you can hire a couple of extra coders. So you all start hacking in features as fast as you can and the app rises in the charts, the revenue rises and everything is looking good. You buy a Porsche.
The code is suffering however from all the hacking and soon you notice that you’re having to do a lot of rework to add a feature. What’s more when you add a new person to the team your output doesn’t seem to increase by one person’s worth, more like half of a person. This is because you’re finding that you’re having to introduce procedures for things, and do documentation and all that overhead that you didn’t have to do when it was just 2 of you. But hey, the money’s flowing in, everything is rosy.
No actually, because if at this point you’re not well on the way to implementing the next killer feature then you’re screwed. Those apps that were designed after yours came to market are going to start coming online. What’s more because they designed in features that you had to hack in later they’re going to be more swish and because their code is still fresh they’re going to be able to implement new features with much less effort than you.
Even if you have got that next feature lined up you’re still in a race that you’re unlikely to win in the log run. You can’t recover your initial velocity, it’s just not possible with a hacked-to-bits code base. It’s always going to cost you more to develop anything than the newcomers to the market. With revenue falling as your market share decreases you can’t afford to throw enough people at the project to brute-force your way back to the top.
Unless you can find some way of drastically increasing your income stream it’s time to put your head between your legs and kiss your Porsche goodbye.
It’s not all doom and gloom though, there are a few ways you can combat this. Not every app / software house crashes and burns quite so pathetically.
For games especially you can release alternative versions – “in space”, “Star Wars edition” etc. that are basically the same code with a few visual tweaks. I could name several game franchises that have been able to do this very well indeed. You can even release “new” games that are substantially the same code as the old and hence don’t need that much development.
If you can use the ascent and some of the initial revenue of the first application to get a second one off the ground then as long as you keep having good ideas for apps you can keep a flow of applications. As one dies the next will become your major revenue earner.
If you use more formal development techniques from day 1 then you’re never really going to have that big burst of activity in the early phase but you’ll be able to build on what you’ve done and maintain your velocity. Competitors will come and go, your app will fluctuate in the marketplace but you stand a reasonable chance of keeping it near the top for a long period of time.
It’s quite fun to look at the successful apps and app developers in the market place and try to work out which they’re doing. Clearly the likes of Microsoft, Google, Facebook etc. are so big they’re largely irrelevant. They need to have the apps, they don’t necessarily need to make money directly from them and they can hurl seemingly unlimited resources at them if needs be.
Most of the smaller firms though you can see quite clearly what their business strategy is.
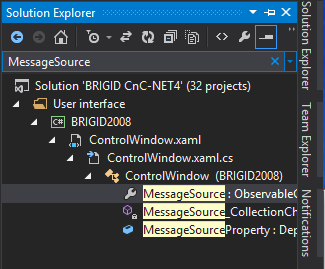
It’s perfectly simple – in Visual Studio 2013 (and I’ve noticed in 2012 also) the solution explorer has a “Search Solution Explorer” function. Initially I assumed it just found files but no, it quite happily finds properties, methods, all sorts.
VS Solution Explorer Search
There are currently 32 projects in our Command and Control solution, as I wrote much of it I know pretty much where everything is but sometimes even I get a bit lost. For new people coming onto the project it must be a real struggle. This could help enormously.
Of course, one could fire up a copy of Cygwin and grep for it, but that’s really not the point!
This is one of the hazards of being in the industry – the Solution Explorer in VS2005 was pretty useless (so everyone used an alternative version). At some point I will have upgraded VS and noticed that the Solution Explorer in the new version was now quite usable. I will have scanned the media on the latest VS release but either I missed or didn’t appreciate the significance of the news about the search function.
Every now and again this happens in the industry – something useful just goes flying past and you don’t realise until months or even years later.
There’s a method in one of Seed’s controller type classes that’s nearly 1000 lines long. How did it get like that? Well basically it’s one big if-then-else construct because C# can’t switch on the type of an object.
Steady on old chap! This article was written many years ago, as from C# version 7 it can switch on type. That doesn’t mean this technique isn’t still valuable, but it’s no longer necessary for a simple switch on type.
So that old Seed method looked pretty much like this:
if(curryObject is MasalaDosa)
{
//a few lines of code
}else if (curryObject is VegetableThali)
{
//a few lines of code
}else if (curryObject is TandooriMas)
{
//a few lines of code
}
//etc. etc.
The real problem with it isn’t the fact that it’s one giant if-then-else structure it’s that each few lines of code is a few too many. It should really be more of the form:
if(curryObject is MasalaDosa)
HandleMasalaDosa((MasalaDosa)curryObject);
else if (curryObject is VegetableThali)
HandleVegetableThali((VegetableThali)curryObject);
else if (curryObject is TandooriMas)
HandleTandooriMas((TandooriMas)curryObject);
//etc. etc.
Naturally you’d think you could use polymorphism to get around the problem;
In reality though sometimes you can’t or sometimes it’s just more practical to use a switch type of affair. As mentioned earlier though you can’t switch on the type of an object in C# you can only switch on type if you’re using C~ version 7 or later. Alternatively you can use a lookup table (actually a dictionary in this case);
class CurryHandler
{
Dictionary<type, action<curry="">> actionTable;</type,>
public CurryHandler()
{
actionTable = new Dictionary<type, action<curry="">>
{
{typeof(MasalaDosa), new Action(HandleMasalaDosa)},
{typeof(VegetableThali), new Action(HandleVegetableThali)},
{typeof(TandooriMas), new Action(HandleTandooriMas)}
};
}</type,>
public void HandleCurry(Curry curry)
{
actionTable[curry.GetType()](curry);
}
//etc. etc.
In C#, Action is a generic type that represents a method, thus Action<Curry> is a type that represents a method that takes a “Curry” as a parameter. So what we’re doing here is constructing a dictionary that links a Type to an Action. So when we call actionTable[curry.GetType()](curry); what we’re really saying is; get the type of “curry” and look that up in the dictionary, then take the associated Action and call that method with the “curry” object as its parameter.
I rather like this pattern, once you understand it I think it’s very clear, more so than a switch statement actually because it gives you a simple reference from Type to Action, you don’t have to wade through a ton of case whatever: do_something(); break; or worse if(whatever is someType)…else if (whatever is someOtherType)… Naturally you don’t have to use a Type as the key, you could use any object as the lookup. You can also use lambda expressions rather than declaring a bunch of new Action… but it’s all too tempting then to write code in the definition of the lookup table and make things messy and unreadable.
It’s not without problems though. As coded above though there’s no protection. If I add a new type of Curry, say DhalMakhani and call HandleCurry with that a KeyNotFoundException will be thrown. We can avoid this easily though and mimic the default: behaviour of the switch statement;
public void HandleCurry(Curry curry)
{
Action curryAction;
if(actionTable.TryGetValue(curry.GetType(), out curryAction))
curryAction(curry);
//else
//do whatever we'd do in default:
}
//etc. etc.
I’ve also never checked how fast it is. It could be much slower than the equivalent if-then-else construct.
One possibly advantageous side effect however is that the logic has been moved out of the programming space into the data space. What do I mean by that? Well actionTable is a variable, you can change it. You can add Actions, take them away or change them at run time. This allows you to do some really clever things but should also be ringing some rather large warning bells. With great power comes great responsibility and the temptation to write code that is simply horrible to read and debug must be avoided, even if what it’s doing is really, really cool.
No doubt this is a clever technique, but it’s far from new. For my next trick I’ll explain how this basic technique can be traced back several decades into early digital electronics.
Like any sane and right minded individual, since a young age a good portion of my Christmas lunch time has been dedicated to avoiding the terror of the Brussels Sprout. Tiny pockets of horrible the little green blighters stalk dinner tables up and down the land at this time of year. Leave just a tiny space on your plate and they mount a full assault, screaming their war cry, “Do you want any sprouts oh go on have one oops that was seven oh well they’re good for you!”
This situation is exacerbated considerably in my case. Living in a rural area has some great advantages, but it has its hazards to. In particular there is the danger of knowing a sprout farmer, which I indeed do. So for me not only is there the danger of copping a sprout grenade at a friend or relative’s house I’ve got two enormous stalks of green ghastliness sat in my pantry staring at me.
A little while ago though a good friend of mine took me aside and whispered in my ear. The trick”, he said, “is to cut them in half and roast them with butter and ginger – lovely!”
I didn’t have any butter but I did have some extra virgin olive oil and some ginger paste, so I put a good glug of oil on a baking tray and mixed in half a teaspoon of ginger paste. After taking the outer leaves off the sprouts I then halved them and put them cut-side-down on the baking tray, threw a pinch of salt over the top and chucked them in the (fan) oven at 180 Celsius for 10 minutes.
As promised they were indeed lovely – the outer leaves a little crispy and slightly sweet and the inner full of ginger-laden flavour.
Like many things the problem with sprouts is not the sprout itself, it’s the fact that many people have no idea how to cook them in a way that I like.
I lost last weekend, although not in a hotel in Amsterdam[1]
I lost the weekend trying to find out what was wrong with my central heating system. What follows is one of the most bizarre journeys of home maintenance that I’ve ever been on.
It all started when I was woken on Friday by a nasty groinching noise – the sort of groinching nose that an expensive electro-mechanical device makes shortly before it relieves you of the contents of your wallet. Worryingly the only two candidates in the next room were the central heating pump and diverter valve, both of which definitely fall into the category of expensive.
I crossed my fingers that some sort of airlock was responsible so bled the pump and a couple of nearby radiators. Hey presto the system burst back into life so I went back to bed.
On Friday night however, whilst I was cooking, I heard a very similar nasty groinching sound coming from the boiler. My wallet yelped, then ran away and hid. Praying to the gods of home maintenance that I wasn’t going to need to call a plumber I hoped that the boiler was simply resonating a sound that came from somewhere else. Regardless, the system was clearly unhappy so I went upstairs and turned the central heating off, but for some reason I can’t quite fathom left the hot water on.
It’s at this point I need to mention that we have a Y-Plan system – the water that the boiler heats can either be used to heat the hot water tank or the radiators depending on the position of the mid-position (diverter) valve.
What happened next surprised me slightly. The boiler fired up and the pump started running – no nasty sounds. So the problem was clearly not the pump and I started to look very suspiciously at the diverter valve. Motor valves are notorious for failing, jamming and just generally going wrong. So I grabbed the “manual” lever and waggled it about. It moved freely but something else interesting happened – the boiler stayed running no matter whether the diverter valve was sending water to the hot water cylinder or round the central heating circuit.
So I left the valve in the mid-position sending hot water to both circuits and we had heat in the radiators. Until the hot water cylinder got up to temperature, which was rather too soon for my liking.
It’s times like this I’m glad that I have a chunky wood burner.
I had things to do on the Saturday but I did manage to get rather a lot of reading done – service manuals for everything in the system and at the end of it all everything was still as clear as mud. One thing that did occur to me though was to measure the boiler input voltage. When the system thought it was heating hot water – regardless of what it was actually heating – there was a something around 240V at the boiler.
If I switched it to central heating it dropped to 150V. So the nasty groinching sound – the sound like something failing to start was probably not because of a mechanical failure but because of a lack of juice.
I breathed a sigh of relief – the fault was electrical. The only component unique to the central heating circuit was the room thermostat my beady eye of suspicion fell upon it. Basically a thermostat is just a temperature controlled switch so I decided to bypass it, just to test. In theory this was a perfectly valid thing to do – if the central heating worked with the thermostat bypassed it would point very strong indeed at the thermostat being at fault. The problem was that the central heating control circuitry is a mixture of two different manufacturer’s wiring instructions and I misinterpreted. So instead of bypassing the thermostat I actually shorted out the output of the programmer. I had a pretty good idea what I’d done when I flipped the “On” switch and heard the almost instant clank of the trip switch flipping “Off”. I may have sworn. Quite a lot. This is because I’m a trained and apprenticed electronic technician and as such this kind of control circuitry is as much, if not more my domain of expertise as an electrician. So making this sort of cock-up is highly embarrassing. I swore some more, to make sure there was enough swearing to communicate just how annoyed with myself I was.
Then I removed the erroneous link wire and prayed once again to the Gods of home maintenance, hoping this time that my stupid mistake hadn’t fried anything expensive. After checking the circuity and components for any physical signs of damage I crossed my fingers and flipped the switch back on again. Initially I did think I’d got away with it. Nothing fizzed, popped or banged, there were no strange smells and nothing appeared to be getting hotter than it should. Nothing that is apart from the boiler which was merrily heating water and the pump was happily whirring away. This was odd because both the central heating and the hot water were turned off at the time.
At least I knew I didn’t need a plumber. I knew who to call; Ghostbusters.
Now I’ve never been particularly frightened by the paranormal so I thought I’d take this opportunity to do some investigation. If I turned the thermostat up to 30 degrees the boiler stopped. If I turned it down to 10 degrees and the boiler started again – the boiler, pump and thermostat were working perfectly.
The real issue though was that I’d made matters worse. Not only did I have the problem of the nasty groinching sound to solve but my central heating was now being operated from beyond the veil. So I grabbed a plastic colander, put it on my head[2] and began my journey into the supernatural. I’d recently short-circuited the output of the programmer and now there was a switching malfunction. I had a pretty good idea what the problem was. Inside the Danfoss CP75 programmer are two relays, one for the hot water circuit and one for the heating. With it all safely isolated I popped the case off the central heating relay and found precisely what I expected – a miniature poltergeist with a teeny-tiny arc welder had mischievously welded the contacts together.
The real explanation is a little more mundane – this is not unusual for a relay that had been massively, but only momentarily, overloaded (say by some idiot shorting the output). As the contacts meet the sheer amount of power melts the surface and they weld together. The breaker then cuts out and prevents further damage. If you’re lucky the damage is only superficial and a little tap will break the weld.
I was lucky. What I did notice however was how much crud there was around the contacts. A few minutes with some fine grade wet-and-dry soon had them looking like new.
I put the programmer back and hey presto the system now works perfectly both for hot water and heating. Apparently so much crud had built up on the relay contacts for the central heating circuit that it was no longer making proper contact at all.
Danfoss CP75
A good result in the end. Sure calling a “heating engineer” might have saved me quite a lot of time – someone with experience would probably have identified the programmer much more quickly than me. But then I wouldn’t have got to run around the house with a kitchen utensil on my head singing old Dean Martin tracks[2]
They’re also unlikely to have identified the output relay directly. Those programmers are no longer made so not only would a “heating engineer” be charging me a premium for a new programmer I’d be facing a substantial bill for wiring it in, too.
[1] If you don’t get the reference search for Lloyd Cole & The Commotions – Lost Weekend [2] Insert “as is the tradition of my people” or “as my faith demands” as you choose.